Kubernetes
Introduction
How it works?
Overview
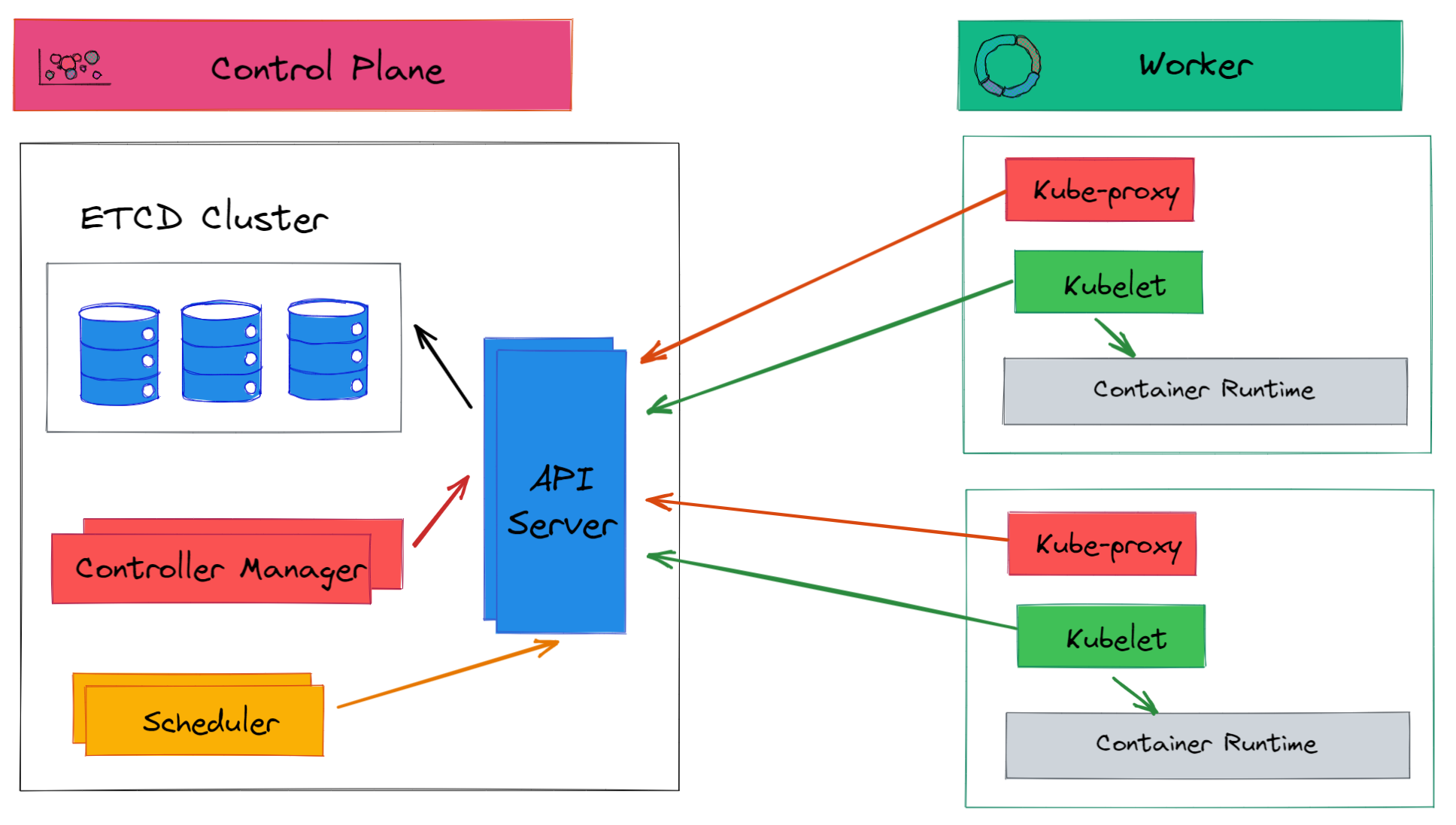
Control Plane
- The API Server is the main entry point and root of the control plane. It exposes the Kubernetes API which allows components and users to interact with the cluster. The API server validates and processes REST requests, which may involve retrieving data from etcd.
- etcd is a distributed key-value store that persistently stores the cluster configuration and state. This includes metadata about Kubernetes objects as well as service discovery information. etcd enables loose coupling between components.
- The Scheduler watches for new pods and assigns them to nodes based on resource availability and other policies. It communicates with the API server to fetch pod specs and write back pod binding results.
- The Controller Manager contains controller processes like the replication controller and node controller that oversee replica sets and node lifecycle management. Controllers reconcile the desired and current cluster state.
- Kubernetes uses Custom Resource Definitions (CRDs) to extend its native API and introduce custom objects. CRDs can have their own controller logic implemented through Operators (e.g. ArgoCD, Keda, Traefik, …)
Nodes
- The kube-proxy agent handles network communication and load balancing for applications running on Kubernetes.
- The kubelet agents run on each node, managing pod/container lifecycles, resource usage, health checking, and overall workload execution based on instructions from the Kubernetes control plane.
More in-depth
Once you discovered the main concepts around Kubernetes, you can look at:
- Kubetools , a large pool of resources around Kubernetes
- KEPS , enhancement tracking repository for Kubernetes
- ArgoCD , a popular “GitOps for Kubernetes” implementation
You can also deep dive into open standards Kubernetes is leveraging, to name a few:
- CNI , container network - I’m recommending The Kubernetes Networking Guide
- CSI , container storage (e.g. for EKS on AWS, it’s the AWS EBS CSI Driver implementing the CSI spec )
- CRI , container runtime
- OCI , container image
- CPI
Tools
- kubectl and helm are must-have tools, kustomize used carefully can be useful
- kubectx to switch easily between contexts and namespaces, I tend to prefer lightweight tools but you can also look at k9s
- watch : Refresh every X sec a command line, e.g.
watch -n 1 kubectl get nodes
Keep clean your kube config
I recommend keeping a cluster config per file to ease the maintenance. For example, this is how my config is structured:
export KUBECONFIG=$HOME/.kube/config:$($HOME/.kube/clusters/add_to_kubecfg.sh)Script add_to_kubecfg.sh:
# .bashrc/.zshrc
# Add all your cluster configurations starting by `cluster` to the folder below
CLUSTER_WORKDIR=$HOME/.kube/clusters
for filename in $(find $CLUSTER_WORKDIR -type f -name "cluster*"); do
KUBECFG+="$filename:"
done
echo $KUBECFGEach cluster has its own file:
{
"apiVersion": "v1",
"clusters": [{
"cluster": {
"certificate-authority-data": "...",
"server": "https://$uuid.$region.eks.amazonaws.com"
},
"name": "arn:aws:eks:$region:$account:cluster/$clusterName"
}],
"contexts": [{
"context": {
"cluster": "arn:aws:eks:$region:$account:cluster/$clusterName",
"user": "arn:aws:eks:$region:$account:cluster/$clusterName",
"namespace": "$namespace"
},
"name": "$clusterName"
}],
"current-context": "$clusterName",
"kind": "Config",
"users": [{
"name": "arn:aws:eks:$region:$account:cluster/$clusterName",
"user": {
"exec": {
"apiVersion": "client.authentication.k8s.io/v1beta1",
"args": ["eks", "get-token", "--cluster-name=$clusterName"],
"command": "aws"
}
}
}]
}Sources
Last updated on